

数据和行业的要素加速了整合。我国家的数据行
栏目:专题报道 发布时间:2025-05-19 11:15
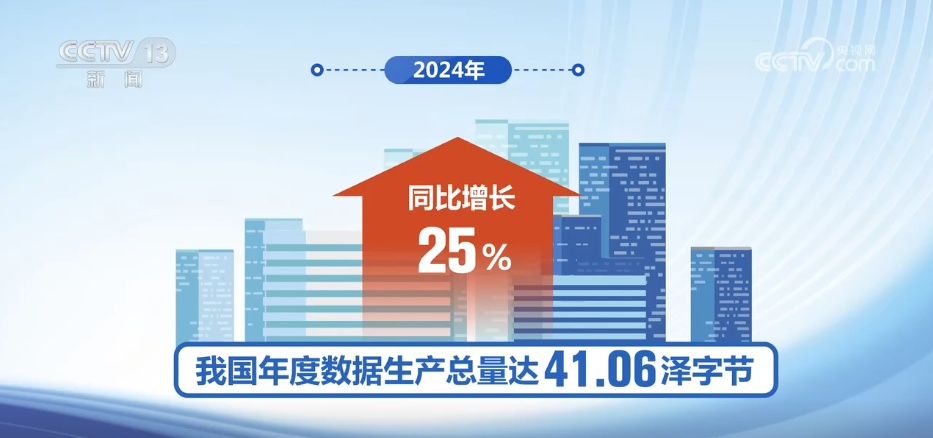 CCTV新闻:5月17日,2025年数据安全开发会议的记者了解到,我的国家将在数据因素产业链中培养和扩展许多流动的企业。估计到2030年,我国数据行业的规模将达到7.5万亿元。作为世界上第一个包括有关劳动因素数据的国家,我的国家首先建立了一个完整的数据产业链。数据显示,2024年,我国家的年度数据生产达到41.06 Zetes,每年增加25%。迄今为止,我国家的数据字段中有超过190,000家相关公司,数据行业的规模已超过2万亿元。根据年的年增长率超过20%,我国家的数据行业的规模将在2030年达到75万亿元。到2029年,国家数据基础设施的结构。2024年,全国范围内或更高的市政级别的平台上开放的本地公共数据数量增加了7.5%,开放数据的数量增加了7.1%,高质量数据集的同比增长了27.4%。在整合数据和行业要素方面,该国加速了开放公共数据共享的障碍,促进公共数据和业务数据的深刻集成以及激活大量的“睡眠数据”。高质量数据集的构建以加速人工智能的发展。当前,数据超过了传统的Pro Factordecision,也是人工智能技术和工业变革成功的主要驱动力。高质量的数据集不仅是在人工智能模型的性能中跳跃的基础,而且是从技术研发到商业实施的整个工业链的重建。那么如何构建高质量的数据集?在Wenzhou,Zhejiang,作为针对数据元素的国家改革的“测试领域”,这里建立了安全系统和合规性,以确保数据元素的较大范围流动,开发交易贸易生态系统,并生成更多的数据“ Live”。技术人员告诉记者,大型数据集的开发主要包括在Pagdata收集,数据清洁,数据注释和质量检查等主要链接中。每个链接都必须根据大规模,适当差异和强大的行业特征的特征来进行有针对性的技术研发和适应。注释和清洁数据是指向高质量数据集构建的主要链接。数据注释教导人工智能通过“标签”(例如图片标签“猫”和“狗”)来“识别世界”。未经预备的数据就像乱码的书籍 - 研究,导致无法人工智能有效地学习;清洁数据通过删除重复和纠正错误来清洁数据,而动荡的数据将直接影响人工智能培训的有效性。人工智能的Pilenlad速度从“模型”以“以数据为中心”的“模型”过渡。高精度数据,高标准和高安全性可以使人工智能系统能够在现实世界中准确获得复杂的法律,并获得出色的模型培训结果。我国数据标签行业的产出超过80亿。可以看出,数据标记是指向高质量数据集构建的主要链接。那么我国家相关行业的发展是什么? 2025年数据安全开发会议发布了“ 2025年高质量研究数据集报告”,通过改变人工智能和大规模模型技术发布,我国家数据行业的输出价值已减少80亿元人民币,高质量数据的构建已经进入了大型和标准开发的新阶段。在2024年,在我国弥补或应用人工智能的企业数量同比增长36%,高质量数据集的数量同比增长27.4%,强烈支持人工智能培训和应用。使用大型模型和数据应用公司的数据技术公司分别同比增长57.21%和37.14%。该报告表明,我的国家目前正在加快高质量数据集的变化和开发,但它仍然面临小型数据库存和低输出,质量不平坦的数据集,缺乏基本的大量指南数据以及低效率数据等问题。
CCTV新闻:5月17日,2025年数据安全开发会议的记者了解到,我的国家将在数据因素产业链中培养和扩展许多流动的企业。估计到2030年,我国数据行业的规模将达到7.5万亿元。作为世界上第一个包括有关劳动因素数据的国家,我的国家首先建立了一个完整的数据产业链。数据显示,2024年,我国家的年度数据生产达到41.06 Zetes,每年增加25%。迄今为止,我国家的数据字段中有超过190,000家相关公司,数据行业的规模已超过2万亿元。根据年的年增长率超过20%,我国家的数据行业的规模将在2030年达到75万亿元。到2029年,国家数据基础设施的结构。2024年,全国范围内或更高的市政级别的平台上开放的本地公共数据数量增加了7.5%,开放数据的数量增加了7.1%,高质量数据集的同比增长了27.4%。在整合数据和行业要素方面,该国加速了开放公共数据共享的障碍,促进公共数据和业务数据的深刻集成以及激活大量的“睡眠数据”。高质量数据集的构建以加速人工智能的发展。当前,数据超过了传统的Pro Factordecision,也是人工智能技术和工业变革成功的主要驱动力。高质量的数据集不仅是在人工智能模型的性能中跳跃的基础,而且是从技术研发到商业实施的整个工业链的重建。那么如何构建高质量的数据集?在Wenzhou,Zhejiang,作为针对数据元素的国家改革的“测试领域”,这里建立了安全系统和合规性,以确保数据元素的较大范围流动,开发交易贸易生态系统,并生成更多的数据“ Live”。技术人员告诉记者,大型数据集的开发主要包括在Pagdata收集,数据清洁,数据注释和质量检查等主要链接中。每个链接都必须根据大规模,适当差异和强大的行业特征的特征来进行有针对性的技术研发和适应。注释和清洁数据是指向高质量数据集构建的主要链接。数据注释教导人工智能通过“标签”(例如图片标签“猫”和“狗”)来“识别世界”。未经预备的数据就像乱码的书籍 - 研究,导致无法人工智能有效地学习;清洁数据通过删除重复和纠正错误来清洁数据,而动荡的数据将直接影响人工智能培训的有效性。人工智能的Pilenlad速度从“模型”以“以数据为中心”的“模型”过渡。高精度数据,高标准和高安全性可以使人工智能系统能够在现实世界中准确获得复杂的法律,并获得出色的模型培训结果。我国数据标签行业的产出超过80亿。可以看出,数据标记是指向高质量数据集构建的主要链接。那么我国家相关行业的发展是什么? 2025年数据安全开发会议发布了“ 2025年高质量研究数据集报告”,通过改变人工智能和大规模模型技术发布,我国家数据行业的输出价值已减少80亿元人民币,高质量数据的构建已经进入了大型和标准开发的新阶段。在2024年,在我国弥补或应用人工智能的企业数量同比增长36%,高质量数据集的数量同比增长27.4%,强烈支持人工智能培训和应用。使用大型模型和数据应用公司的数据技术公司分别同比增长57.21%和37.14%。该报告表明,我的国家目前正在加快高质量数据集的变化和开发,但它仍然面临小型数据库存和低输出,质量不平坦的数据集,缺乏基本的大量指南数据以及低效率数据等问题。 下一篇:没有了